Spoken Wikipedia
The Spoken Wikipedia project is an organization on Wikipedia that creates audio recordings of Wikipedia articles. I have created a number of recordings for this organization.
My Wikipedia handle is Mangst.
 How I record articles
How I record articles
How this webpage works
How I record articles
Last updated: 12/19/2011Software
I use Audacity to make the recordings. Audacity is a free, open-source, digital audio editor that's available on all operating systems. The Spoken Wikipedia page uses this software when giving instructions on how to record articles, so I decided to use Audacity so that I could follow along with the instructions. But it works well and I have no desire to switch to anything else.
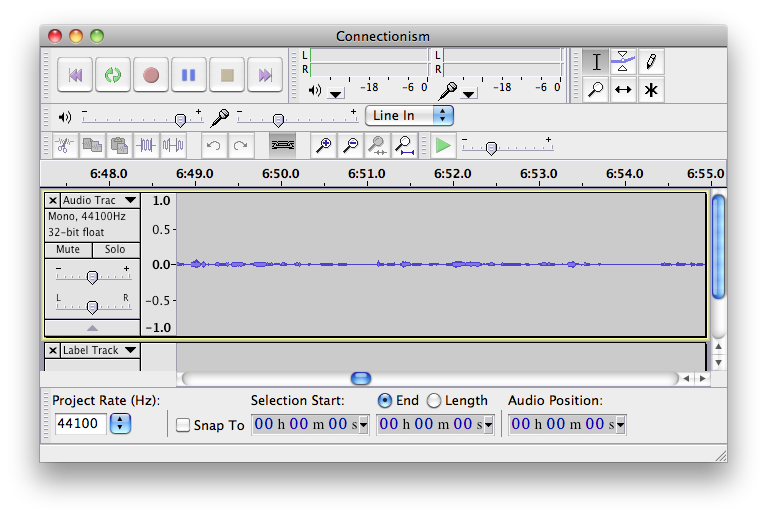
A screenshot of Audacity running on my Mac.
My recording process
I usually make each recording in two or three separate sessions of about 3-4 hours each, depending on the size of the article. I find that, if I can record for long stretches of time, I get into a good "groove" and the quality of my recording increases. I start each session by getting a cup of warm water so my throat doesn't get dry (don't drink juice or soda because they have sugar, which makes your mouth produce mucus). Then, I warm up by reading a couple paragraphs of the article. Even though I'm just warming up, I still record myself talking because I find that the fact that I'm being recorded has an effect on how I speak (it makes me a little nervous). So, I record myself warming up, even though I'm just going to throw away the recorded audio.
After I've warmed up, I start the real recording. I record the article one section at a time (each Wikipedia article is divided up into a number of sections). If I make a mistake, I re-read the sentence without stopping the recording. When I finish recording the section, I stop the recording and play back the section I just read, deleting the mess-ups and correcting any other mistakes I didn't notice before. Then, I move on to the next section and repeat the process until I finish.
As I'm recording, I like to add labels to the audio file to mark where each section begins (you can do this in Audacity by pressing Ctrl-B). This makes it easier to update the recording later on because it allows me to jump right to the section I need to edit.
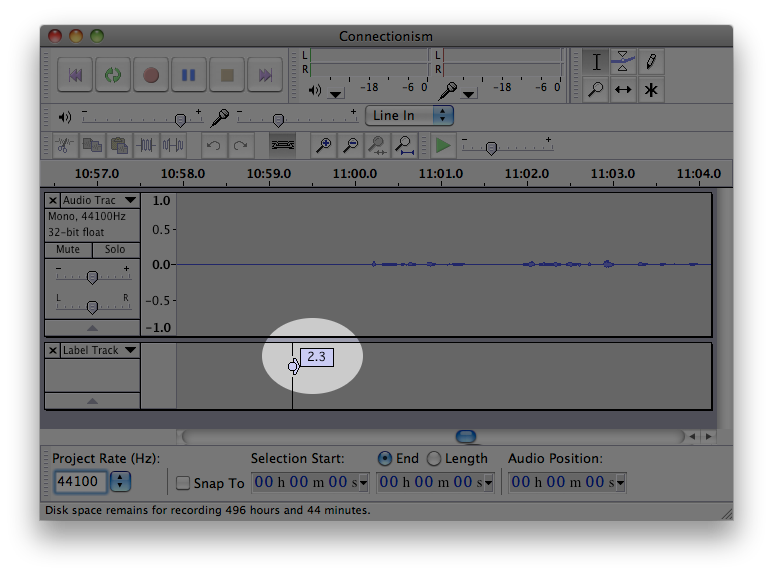
Labels are displayed below the audio track.
Once I've finished the entire article, I listen to the whole thing one more time to catch any other mistakes that slipped through. Then, I perform the following post-processing effects on the recording:
- Remove noise - Even though it's very quiet where I live, there's still a tiny bit of background noise which I can kind of hear after I've Normalized. To remove this noise, select about 5 seconds of sound where you're not talking, then go to "Effect > Noise Removal" and click the "Get Noise Profile" button. Then, select the entire audio recording by pressing Ctrl-A and go to "Effect > Noise Removal" again. This time, click "OK" to perform the noise removal using the noise profile you just created. You should definitely do this if you live somewhere noisy, like next to a busy street.
- Normalize - This will amplify everything to a good volume without making the recording sound crackly.
- Bass Boost (with a small value of about 4 dB) - This makes your voice sound sexier. :)
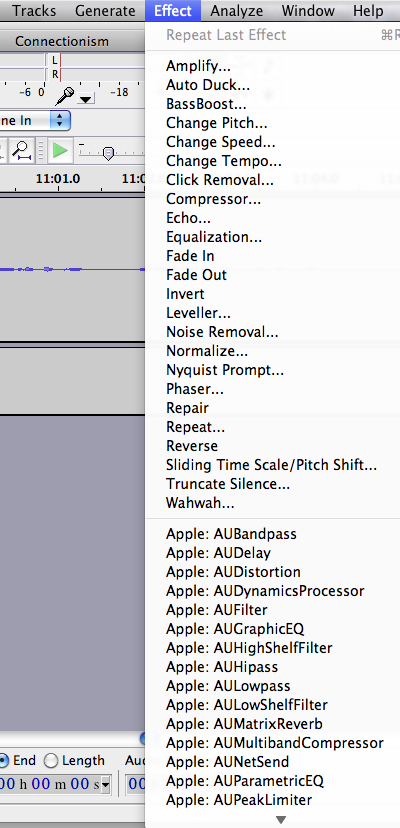
Audacity comes with a number of effects that you can apply to your recording.
Then, without saving, I export the recording to an OGG file, then close the recording without saving. I don't save it because I don't want to save the post-processing effects that I made--I want to keep the recording as raw as possible so that I can reopen it later and make edits if I need to. The idea is that you should only run these post-processing steps when you're ready to export to OGG and upload the file to Wikipedia. You should never save the post-processing changes.
How to start and end an article
Before reading the text of the article, I start each recording by reading the article title, saying that it's from Wikipedia, then saying the date that the recording was made on (or the date the recording last updated). For example:
Neural network. From Wikipedia, the free encyclopedia, at en dot wikipedia dot org. Recorded on November 27th, 2011.
Then, I read the article introduction, followed by the table of contents. When reading the table of contents, I only read the major sections--I don't read the minor sections or the sections that I won't be reading. For example, I would only read sections 1, 2, 3, 4, 5, and 6 from the table of contents below (section numbers can be enabled by logging into Wikipedia, going to "My Preferences > Appearance" and checking "Auto-number headings"). I leave out everything else, including the sub-sections, because I feel it would overwhelm the listener:
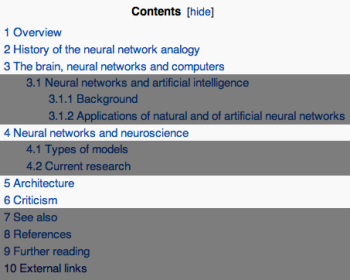
I would only read the white sections from this table of contents.
At the tail end of the recording, I state the title of the article, say that it's from Wikipedia, state the date the recording was made, and then read the licence. For example:
You have just finished listening to Neuroscience, from Wikipedia, the free encyclopedia. This article was recorded on November 27th, 2011. This sound file and all text in the article are licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License, available at http://creativecommons.org/licenses/by-sa/3.0
Some people like to also mention their names at the beginning and/or end of the recording, but I don't do that.
Updating a recording
With every change that is made to an article, your audio recording becomes less and less accurate. Because of this, I like to update my recorded articles every six months or so to help keep my recording in-sync with the latest revision of the article.
To help me do this, I create a Word document that contains the text of the old revision (the revision I last used to record the article), with the changes that I need to make highlighted in yellow. I open the old revision from the "View History" screen, and then just copy and paste the entire webpage into Word. I then edit this document with the changes I need to make. Text that needs to be added I highlight in bright yellow, and text that needs to be removed I highlight in yellow and give the "strikethrough" formatting. It takes time to do this, but it makes updating the recording so much easier. It's worth it, trust me.

My Word document tells me exactly what changes I need to make to my recording.
Determining what changes were made to the article can be tricky. If the article hasn't changed too much, Wikipedia's "Compare selected revisions" feature is usually enough (click on the "View History" tab, select the two revisions by clicking on the radio buttons, then click "Compare selected revisions"). However, if the article went through more complicated changes, then you're going to have to inspect each revision manually, using the "Compare selected revisions" feature only to figure out the location of each change. "Compare selected revisions" also points out changes that aren't relevant to an audio recorder, like changes related to formatting or references, so it often looks like there's more changes than there actually is.

Wikipedia lets you compare two revisions of the same article side by side.
Other tips
- Turn down your microphone sensitivity. Doing this will help to remove pops (from making the "p" sound), breathing sounds, and the sounds of your lips smacking together. It also helps to remove background noise. It's OK if the recording is hard to hear when you play it back--running the "Normalize" post-processing step will automatically increase the volume to a good level.
- Many Wikipedia articles contain images, and each image typically has a caption. Some Wikipedia audio recorders will go so far as to describe the image and/or read the image caption. My feeling is that this distracts from the flow of the main text, so I don't do this.
How this webpage works
Last updated: 12/22/2011The list of articles you see is not hard-coded into my website--it is screen-scraped from my Wikipedia user page. What happens is it loads the HTML code of my user page, looks for the table where I have my list of articles, and then parses the data from the table. Luckily for me, the HTML code of Wikipedia is very well-structured, so I can treat it just like XML. This allows me to load it into a DOM (document object model) and then run XPath queries against it to extract the data I want.
 View the source
View the sourceNot all websites have well-structured HTML like Wikipedia, however. These websites are much more difficult to scrape because they're harder to load into a DOM and parse with XPath. Also, even if the HTML is well structured, it could be that the data isn't organized in a consistent way, making it hard to determine where in the webpage to get the data from. But the truth is that HTML isn't meant to encode raw data. It's a markup language that defines how the data is displayed in a web browser. Other data formats, such as JSON and XML, were specifically designed for encoding raw data.
I also cache the data on my own web server. This allows my website to read the data from the cache, instead having to load the page from Wikipedia every time. When the last modified date on the cache file gets to be older than one hour, it scrapes the Wikipedia page again, incase any changes were made to it in the last hour. It caches the data in an XML file.
<?xml version="1.0"?> <spokenWikipedia> <article url="http://en.wikipedia.org/wiki/Battle_of_the_Somme" title="Battle of the Somme" featured="false"> <date>2009-01-31</date> </article> <article url="http://en.wikipedia.org/wiki/NeXT" title="NeXT" featured="true"> <date>2009-02-10</date> <date>2010-09-26</date> <date>2011-04-09</date> <date>2011-10-16</date> </article> [more articles...] </spokenWikipedia>